- a: よ (maybe ٳ )
- akesi: 單 or ꎖ/ꐾ/ꇆ/ꉀ or ቿ or ꗊ/ꗵ/ꗶ or ∰
- ala: ✕/×/X/᙭/╳
- alasa: ➵
- ali: ∞/ထ/Ꝏ
- anpa: Џ/џ (maybeࢠب ) (or Ꚏ/ꦉ)
- ante: ≍/ᳲ
- anu: Y/Ү/丫
- e: ⨠ (or » or ≫ or even ⪼)
- en: +/✚/⼗
- esun: ℒ/୫
- ijo: ◯/〇/ഠ/ⵔ/೦
- ike: ◠ (or ꒢/ᴖ/︵)
- ilo: ዋ/ⴔ
- insa: ⨃ (ษ)
- jaki:ھ /ණ/༳ (arabic PBUH looks better but that would prob be offensive)
- jan: ꆰ/႙/ꂮ/ꆜ
- jo: ၉/Ꮆ/ᕦ??
- kala: ꩳ/ᘗ or ⧕/ꎫ
- kalama: ෪??
- kama: 𓂽
- kasi: ܤ
- ken: K/K/ᛕ/ᴋ
- kepeken: ቋ
- kin: ꎰ (or ꘎(??))
- kipisi: ٪ (or ⸓ %)
- kiwen: ⌔ (or ⯂, but thats filled)
- kon: ⧚ (⮁) (or ꘒ/🅍)
- kule: Ꙙ/ꙙ/Ԭ
- kulupu: ஃ/༜/⛬/∴
- kute: ꎌ (ꊐ, ᑓ??)
- la: ᑐ orﬤ or ᧑
- lape: ⊸ (or Ю/ю)
- laso: ꖏ/Ⰺ
- lawa: ፁ/ꆧ
- leko: ⧈/回
- len: 吊 badd
- lete: ӿ (or Ӿ or 氺)
- li: ᐳ or 〉 or ≻
- lili: v/˅/ᨆ
- linja: ᔓ/〰/ྊ
- lipu: ⧠/ㅁ/□
- lon: ߸/∸ (maybeٹ / ݖ) (or ⼇/䒑/亠/ᅩ/ㅗ)
- luka: Њ or 𓃀
- luka: Ꮑ/л/ת /ᕄ
- lukin: ∢/⋖/𓁻
- lupa: ᑌ/ꓴ/⋃/Ս/
- ma: ⴲ/⊕
- mama: ჹ/Ზ or 呂
- mani: ᴕ/ȣ
- meli: ⍝/ၐ (♀)
- mi: ᑭ (୧/⍴/የ)
- mije: ⍜ (♂)
- moku: ሸ (or Ѭ, గ??)
- moli: ⚇/〷/༞/ᕯ/䍑
- monsi: ·[ or [ or ㆎ/ᆡ
- monsuta: ෴
- mu: ൠ/ტ
- mun: ☽/ᗤ
- musi: ☋
- mute: ꠲ (𐤛 /|||/川)
- namako: ⊹/✢ (or ✜)
- nanpa: #/ⵌ/ꖛ
- nasa: ඉ/೨/꡴
- nasin: ⏃/⍋ or ∱/⨙/ተ or Ꙟ/↟
- nena: ᑎ/ꓵ/⋂/Ո/
- ni: ↆ/↓/⇣
- nimi: ▭ (ᄆ/ᆷ)
- o: ! (or ䷕䷣䷭)
- oko: ⵙ/☉/⊙/๏/Ꙋ/⨀
- olin: ଞ
- ona: ᓄ (و /ڡ / Ꝺ)
- open: ㅂ (or ម)
- pakala: ⭍/↯ or ꉅ (maybe +box enclosing combining character)
- pake: ⏉/T/ㅜ/丁
- pali: ዳ/ዶ/ጰ/ꈸ/ꈻ
- palisa: ꧰/ꄲ
- pan: 巛 (unfortunate)
- pi: ட (∟/⺃/ᥨ/ㄴ)
- pilin: ❤/♥ or ఇ
- pimeja: ⨻/Ѧ/⟁/Ⳛ/Ⱑ
- pini: 工/ꕯ/エ/Ɪ
- pipi: 半/丰/丯/ŧ/手/⺨ or Ї/ギ or ⶩ
- poka: ᑘ (hard to see)
- poki: Ⳙ/ꦥ/ப/⼐/ប
- pona: ◡ (or ꒡/ᴗ)
- pu: ⌻??
- sama: =꓿꞊═₌゠=᐀ᆖꘌ⚌〓㆓⼆
- selo: 爪/爫/ጠ
- seme: ?
- sewi:ﷲ /ﺳ
- sike: ㉧/⭗/⦾/៙
- sin: 𝇘
- sina: ᑲ (ꕃ/b/ⴆ)
- sinpin: ]· or ]
- sitelen: ꘖ (or ⚂)
- sona: 畄/尚
- soweli: Ლ??
- suli: ꓦ/ᐯ/ⴸ
- suno: ༓
- supa: ∏/丌
- suwi: ^.^
- tan: ⤺ or ↶/⮏
- taso: ㅓ/⊣/ᅥ
- tawa: ႔ or 𓂻
- telo: ≈ (⮂)
- tenpo: ◷/⏲
- toki: ⛣ (ȫ/ӧ)
- tomo: ⌂/☖
- tu: ॥ (𐤚 /||/꡷)
- unpa: ꕢ/Ꮘ/ᳪ/⅌/Ⰲ
- uta: ᗜ/⯋/⩌
- utala: ⤩
- walo: ꕖ
- wan: 1(ߗ is better but is R-L)
- waso: ᔱ/ᔨ/ᔳ
- wawa: 𓁏 or \o/
- weka: ⤫??
- wile: Ꞷ/ω/ꞷ/ധ
I heard blissymbols also has a few overlapping glyphs but sadly blissymbols arent unicode.
I tried to see if anyone else had tried to do this before me but couldnt find anything (in retrospect, i didnt really look hard enough) oop.
shapecatcher seemed very promising but wasnt really working that well and had a few restrictions (CJK characters not in database even though they could be relevant, have to draw without eraser whereas i would prefer to directly upload the sitelen pona glyphs) and it wasnt giving me satisfactory results for many of the drawings. sadly the code is not open source so i had to look into the underlying research. im not an academic tho so it was fun trying to parse it into anything useable.
So I decided hey I do coding what if I made a thing that generates a picture for every Unicode character then reverse searches sitelen pona to find close matches. Funny thing is I’d never coded anything to do with image manipulation but that’s a learning opportunity. I decided to use python and opencv because idk those r supposed to b good. So like I sketched up a prototype python script which is just a quick experiment that opened and normalised two images and compared them with cv.matchShapes


as u can see it gives a much higher number for the image that’s been flipped and scaled vs two unsimilar images. Then I made it a bit more useful by making it search a bunch of images for the most similar so like a reverse image search but shape matching using Zernike moments or whatever. updated python script

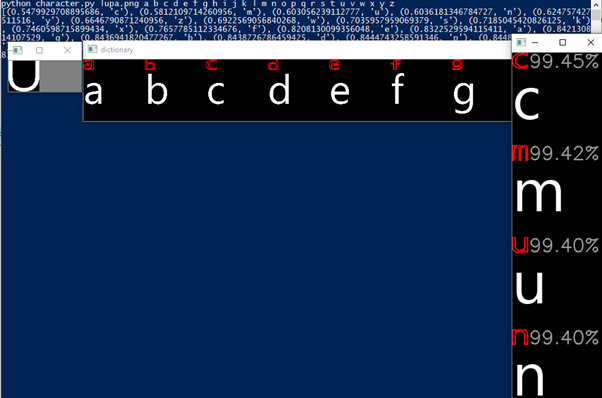
You may be wondering why it came up with ona > mi and c > u, that’s because the shape analysis method is “rotation invariant” so it doesn’t care about what rotation things are, which is annoying because we do care. I added a thing which lets u use other methods that value different things differently and theoretically some r supposed to be rotationally variant but uh basically things didn’t really workt hat well but shhh here u go

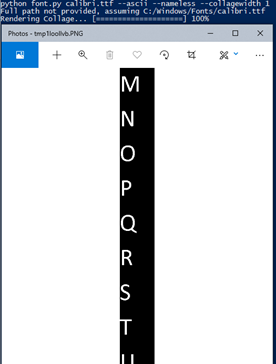

Ok this one has even more complex command line usage which I cant really remember that well but like u input what font u scan from (and u can import multiple fonts and specific code ranges for them) and then what letter u wanna search (enter it by its codepoint number that the last program showed us) (also u can do multiple and it wont have to render the unicode image collage dictionary thing each time) characterhu.py
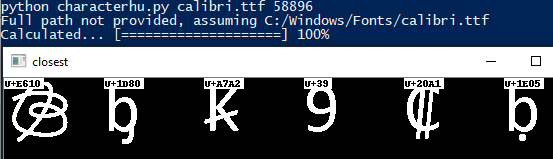

I also wrote a quick messy js thing for generating an input that would use all the fonts without duplicating any letters maybe but the code corrupted. Anyway I looked at what this gave and it worked but it was utter shit none of the results were good and so I thought hmm why and thought maybe im approaching this wrong im doing shape analysis which is good for recognising when somethings been transformed a bit but I want things that look like the original not things that look like a deformation of the exact original. So I switched to a new plan which was to
scan(<array_of_charpoints>) and ittl start cycling thru them and u can click a pixel to make it filter to only ones with that pixel drawn, click again and only ones with that pixel undrawn, click again and to make it not care.
but to make it more useful u can use custom fonts do addFont(fontName, pathToFont) [the fontName doesn’t rlly matter] then the next time u do scan() itll use that font to generate the thing.
Also u can go into the html document and change the globalwidth & globalheight so it is more pixelated and less laggy & memory intensive.
To get the most out of the custom font things u can use the results from font.py (with -T enabled) and make a bit of code that does like addFont(…).then(()=>{scan(<arrayOfCodePointsGivenFromFontPy>)})
but so yeah I tried that and it kinda worked but it got very laggy and I didn’t like the flashing thing in my face when im super tired and even setting the css backgroundcolor to be dark didn’t fully fix it eh so I went to my final method..
gimmeRunnable(<someIntFrom0to20>) ) to make sure I didn’t have to look at duplicate glyphs in each font) and I had a big list of them all but in the months between then and now Sublime deleted that list (I never saved it bc im a poop) so now im left with just the one you see at the top.